
It all started when I wanted to check the performance of JSON of MYSQL and JSONB of PostgreSQL
I am a big fan of PostgreSQL for its power and I have read N number of articles showing why PostgreSQL is better than MySQL
Various Benchmarks and research done to prove that Postgres is indeed faster than mysql.
But I was naturally curious then why lot of big organizations are still using mysql as their primary RDBMS database at scale. I have had first hand experience of using both mysql and postgresql for various enterprise clients and I know tech giants like flipkart, uber uses mysql as well.
In fact, Uber have migrated from PostgreSQL to MySQL ( as per their engineering blog here)
With all this conflicting information - I wanted to see for myself if PostgreSQL is indeed faster and better than mySQL for JSON especially
In this article, I am covering only the Read Operation (SELECT) here and this is my personal experiment and the outcomes.
So lets get started
Tools used / Prerequisites
- MYSQL 9
- PostgreSQL16
- Vegeta - For Load Testing and Graphs
- FastAPI - To create a HTTP web service
- Psycopg2 - Library to connect FastAPI to Postgres
- Pymysql - Library to connect FastAPI to Mysql
- Mac M3
- TablePlus (SQL client tool - You can choose as per your choice)
The DB Schema and Test Data
I started with few rows of data in both MYSQL9 and PostgreSQL16 - For the performance validation and to evaluate the JSON specific performance, I have used multilevel nested JSON data
My table in both DBs have same schema
- id - auto incremented int
- user_data - Field/Column containing the JSON data
Here is a sample JSON data format I have taken and used
{"user": {"id": 12345, "name": "John Doe", "email": "[email protected]", "orders": [{"date": "2023-09-12", "items": [{"item_id": "ITEM001", "quantity": 1, "shipping": {"address": {"city": "Metropolis", "street": "4321 Oak Avenue", "zipcode": "67890"}, "carrier": "FedEx", "expected_delivery": "2023-09-15"}, "description": "Gaming Laptop", "price_per_unit": 200.50}, {"item_id": "ITEM002", "quantity": 1, "shipping": {"address": {"city": "Metropolis", "street": "4321 Oak Avenue", "zipcode": "67890"}, "carrier": "FedEx", "expected_delivery": "2023-09-15"}, "description": "Mechanical Keyboard", "price_per_unit": 50.25}], "total": 250.75, "order_id": "ORD123456"}, {"date": "2023-08-25", "items": [{"item_id": "ITEM003", "quantity": 2, "shipping": {"address": {"city": "Metropolis", "street": "4321 Oak Avenue", "zipcode": "67890"}, "carrier": "UPS", "expected_delivery": "2023-08-28"}, "description": "Wireless Mouse", "price_per_unit": 25.50}, {"item_id": "ITEM004", "quantity": 1, "shipping": {"address": {"city": "Metropolis", "street": "4321 Oak Avenue", "zipcode": "67890"}, "carrier": "UPS", "expected_delivery": "2023-08-28"}, "description": "HD Monitor", "price_per_unit": 49.99}], "total": 100.99, "order_id": "ORD123457"}], "address": {"geo": {"lat": "40.730610", "lng": "-73.935242"}, "city": "Gotham", "street": "1234 Elm Street", "zipcode": "54321"}, "preferences": {"newsletter": true, "payment_methods": [{"type": "credit_card", "expiry": "12/2024", "provider": "VISA", "last_digits": "1234"}, {"type": "paypal", "email": "[email protected]"}], "sms_notifications": false}, "phone_numbers": [{"type": "home", "number": "+1-202-555-0170"}, {"type": "mobile", "number": "+1-202-555-0111"}]}}
Both databases and their users table had 12 rows of such data ( similar but not the same)
you can download the SQL dump from Github repo
The FastAPI WebApp
I have created a simple FastAPI web application with two endpoints /postgres and /mysql accessed through HTTP GET
Upon invocation, They create a new connection to the DB and close the connection after the use
To ensure that no caching involved at the python fastapi front - I decided to use the pure python libraries such as psycopg2 and pymysql to connect to DB instead of any ORMs like SQLAlchemy
MySQL has native Query Caching enabled by default, to avoid this - we have added Now() method into our SELECT query and this is a easy hack to make sure that our query runs without cache
Here are the SQL queries we have used on both DBs
MySQL Query using JSON_TABLE
SELECT
u.name,
SUM(orders.total_order_value) AS total_order_value,
NOW()
FROM
users,
JSON_TABLE(user_data, '$'
COLUMNS (
name VARCHAR(255) PATH '$.user.name'
)) AS u,
JSON_TABLE(user_data, '$.user.orders[*]'
COLUMNS (
total_order_value DECIMAL(10, 2) PATH '$.total'
)) AS orders
GROUP BY
u.name;
PostgreSQL Query using JSONB method
SELECT
user_data->'user'->>'name' AS name,
SUM((ord->>'total')::DECIMAL(10, 2)) AS total_order_value,
NOW()
FROM
users,
jsonb_array_elements(user_data->'user'->'orders') AS ord
GROUP BY
user_data->'user'->>'name'
Installation of the DBs and Version
For this testing I have used Home Brew Edition of both MYSQL and POSTGRESQL
brew install postgresql@16 brew install mysql
As I have mentioned earlier the following versions are taken and installed on my local
- mysql - version 9
- postgresql - version 16
I have also created some super user accounts so that I can connect from my FastAPI code to the Database servers.
FastAPI Server Code
This is the python code I have used after various permutations and iteration as of 2nd October 2024, as I am writing this article.
Please check the Github repo link for the latest code and other assets and artifiacts
from fastapi import FastAPI, Depends
from pydantic.types import Json
import uvicorn
from pydantic import BaseModel
import os
import pymysql
from dotenv import load_dotenv
import psycopg2
import psycopg2.pool
import psycopg2.extras
from loguru import logger
load_dotenv()
app = FastAPI()
pool = psycopg2.pool.SimpleConnectionPool(
minconn=1,
maxconn=1,
host=os.environ.get("PG_HOST"),
user=os.environ.get("PG_USER"),
password=os.environ.get("PG_PASS"),
database=os.environ.get("PG_DB")
)
async def get_pg_pool_conn():
conn = pool.getconn()
try:
yield conn
finally:
pool.putconn(conn)
async def get_pg_connection():
# Using psycopg2
return psycopg2.connect(
host=os.environ.get("PG_HOST"),
user=os.environ.get("PG_USER"),
password=os.environ.get("PG_PASS"),
database=os.environ.get("PG_DB")
)
async def get_mysql_connection():
return pymysql.connect(
host=os.environ.get("MYSQL_HOST"),
user=os.environ.get("MYSQL_USER"),
password=os.environ.get("MYSQL_PASS"),
database=os.environ.get("MYSQL_DB"),
cursorclass=pymysql.cursors.DictCursor
)
@app.get("/postgres")
async def get_postgres_data(conn=Depends(get_pg_pool_conn)):
with conn.cursor() as cur:
cur.execute("""SELECT
user_data->'user'->>'name' AS name,
SUM((ord->>'total')::DECIMAL(10, 2)) AS total_order_value,
NOW()
FROM
users,
jsonb_array_elements(user_data->'user'->'orders') AS ord
GROUP BY
user_data->'user'->>'name';""")
data = cur.fetchall()
return {"data": data}
@app.get("/mysql")
async def get_mysql_data():
mysql_conn = await get_mysql_connection()
# Create a cursor
with mysql_conn.cursor() as cur:
# Note this example doesn't handle any database errors for simplicity.
cur.execute("""SELECT
u.name,
SUM(orders.total_order_value) AS total_order_value,
NOW()
FROM
users,
JSON_TABLE(user_data, '$'
COLUMNS (
name VARCHAR(255) PATH '$.user.name'
)) AS u,
JSON_TABLE(user_data, '$.user.orders[*]'
COLUMNS (
total_order_value DECIMAL(10, 2) PATH '$.total'
)) AS orders
GROUP BY
u.name;""")
data = cur.fetchall()
mysql_conn.close()
return {"data": data}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Caveats
- To run this code - you need to install the requirements and provide required environment variables using .env file - check the github repo for samples
- Despite the above code contains the Connection Pool logic for the postgres - I started using it for the last rounds of testing - initial tests were performed without connection pool logic on PG
- This is not production ready and designed for only local testing
Vegeta command references
For load testing and Plot creation - I have used vegeta - while there are other tools like K6s from Grafana and Locust etc. I found vegeta to be simple and powerful and I have been using it for years
I am giving some reference commands here that I have used as part of my tests
For more reference on vegeta refer the github link
# To run the test echo "GET http://localhost:8000/postgres"|vegeta attack -rate 50 -duration 2m > pg16-get-50qps.bin echo "GET http://localhost:8000/mysql"|vegeta attack -rate 50 -duration 2m > mysql-get-50qps.bin # To create a plot/graph vegeta plot – title="PG results" pg16-get-50qps.bin > pg16-get-50qps.html vegeta plot – title="MYSQL results" mysql-get-50qps.bin> mysql-get-50qps.html
Now let us start with our test
Round 1 - Using the Default Settings on both DB
This round of testing was performed after the installation and user creation and data insertion with no configuration change whatsoever.
we have set the Vegeta to attack the http://localhost:8000/mysql and http://localhost:8000/postgresql endpoint at 50 requests per second for 2 minutes
Totally - we are going to make 6000 requests at 50QPS rate and we will keep at this rate for all the upcoming tests too
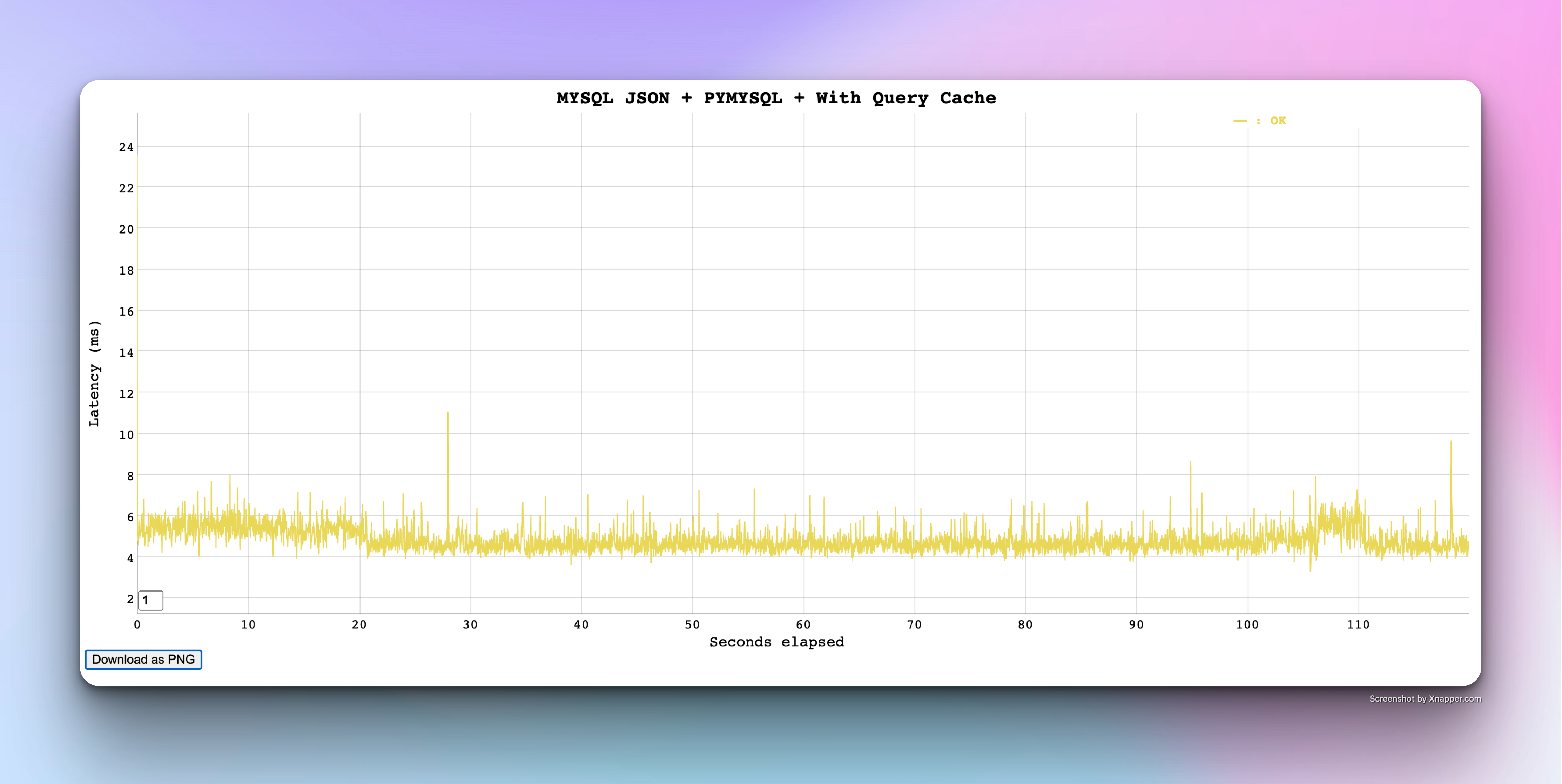
MYSQL results with Default Settings
MYSQL performs great with just default settings and tuned for performance - With no changes I was able to achieve great performance and zero failures with low latency
Update: After publishing the initial version of this article - I came to know that from MYSQL Version 8, the QueryCache feature is removed
Refer to this link for more information
Thanks to Karthik P.R from mydbops for correcting this.
POSTGRESQL result with no changes
Now its a time for PostgreSQL results with no configuration changes ( not even initdb which optimize the PG performance little bit)
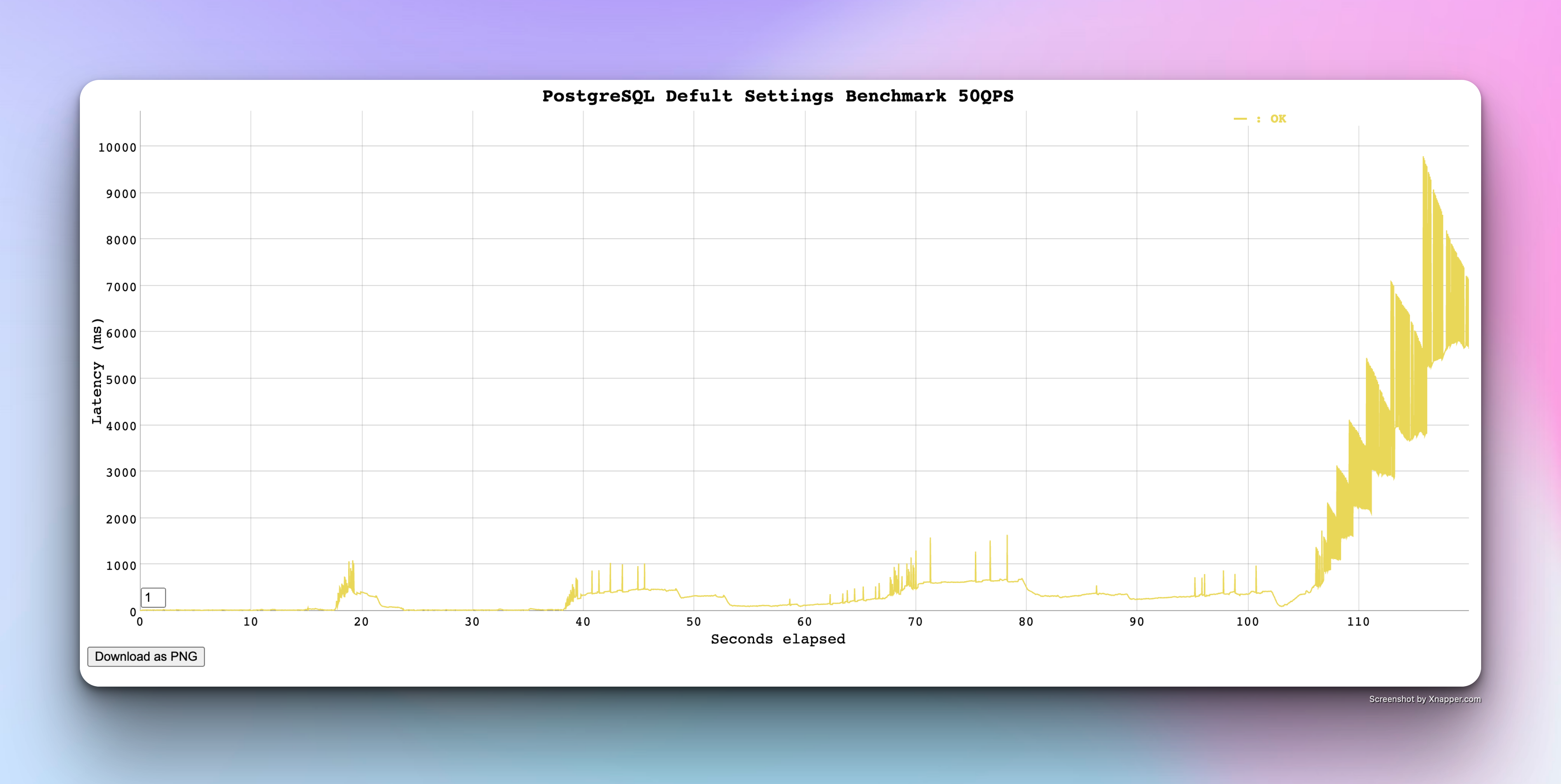
I was truly shocked to see this result but I blamed the configuration and hoped that initdb would solve this and make the line flat and bring down the latencies low
Now I have run the initDB which sets few attributes like
- max_connections
- shared_memory
- shared_buffers size
- timezone
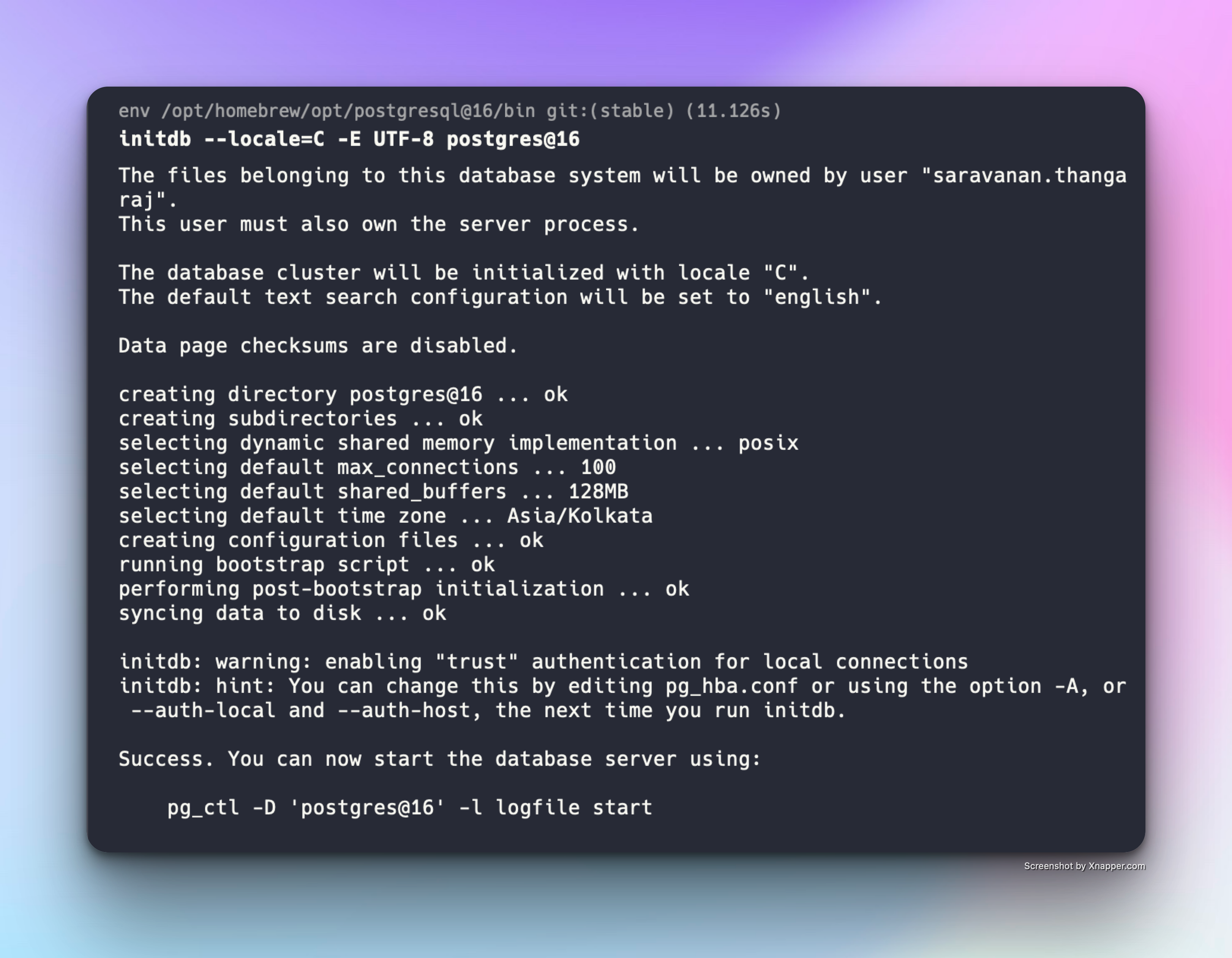
Now the initdb is done and lets run the second attempt
Note*: Since MYSQL had a better performance for 6000 requests at 50QPS - the next rounds are going to be focusing on meeting the same benchmark in PostgreSQL and what are the various factors that attribute to the Postgres performance
Round 2: PostgreSQL rerun after InitDB
After running the InitDB changes, I was hopeful to meet the baseline performance of MYSQL but here are the results
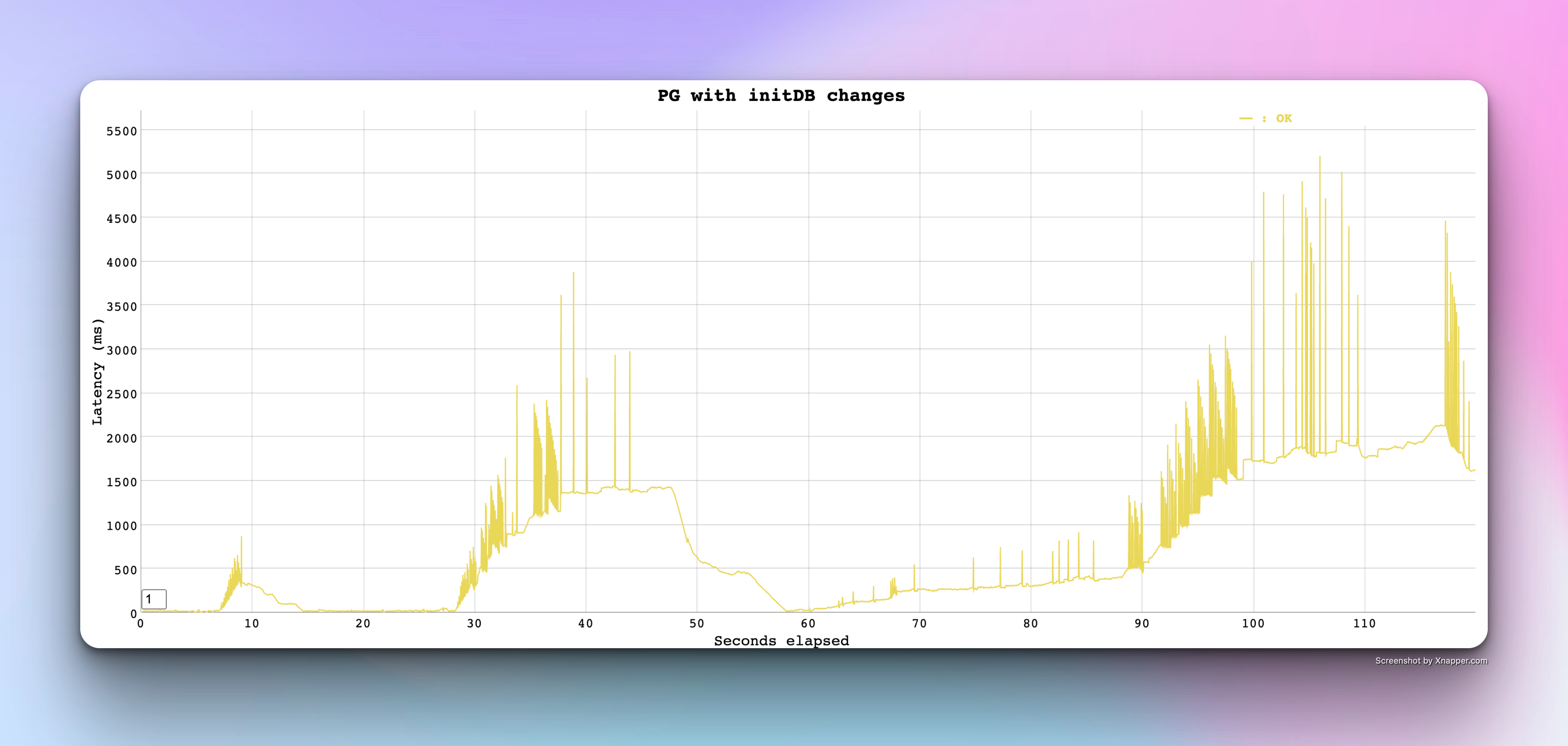
It was not much of a help but there was a slight change in terms of performance - Latency reduced by 50% overall but still cannot match MYSQL performance
So I continued with further tuning to prove that Postgres is better for JSON
Round 3: PostgreSQL rerun after config Changes
When I checked the configuration values that was shipped in, I found there were lot of scope for performance tuning
I changed the following values and retried
- max_connections = 200
- shared_buffers = 1024MB
- work_mem = 512MB
- dynamic_shared_memory_type = posix
- max_parallel_workers = 10
- effective_cache_size = 4GB
This is the result after the aforementioned changes
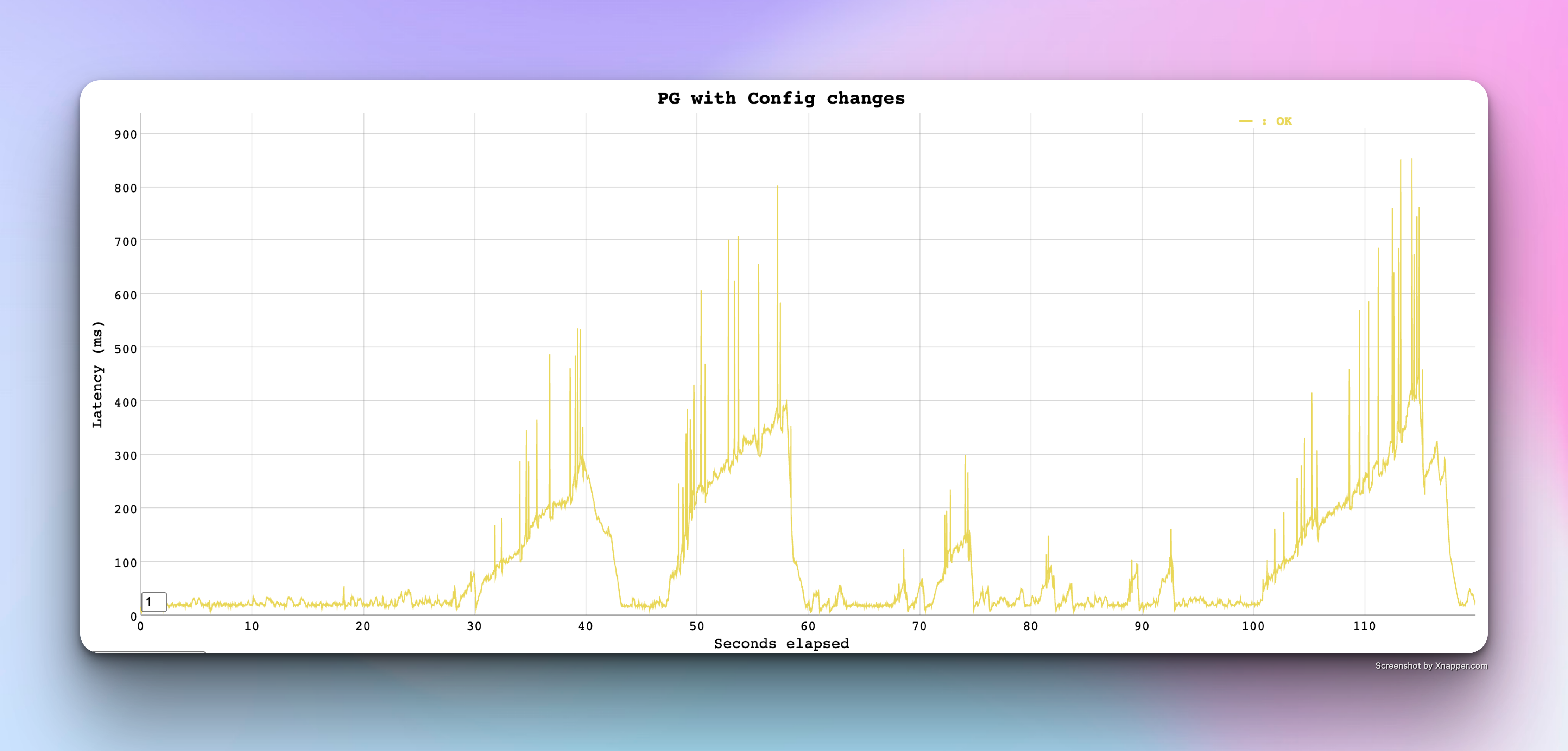
I did various attempts to match the mysql base line performance as part of Round 2
Here are some of the notable changes and their results
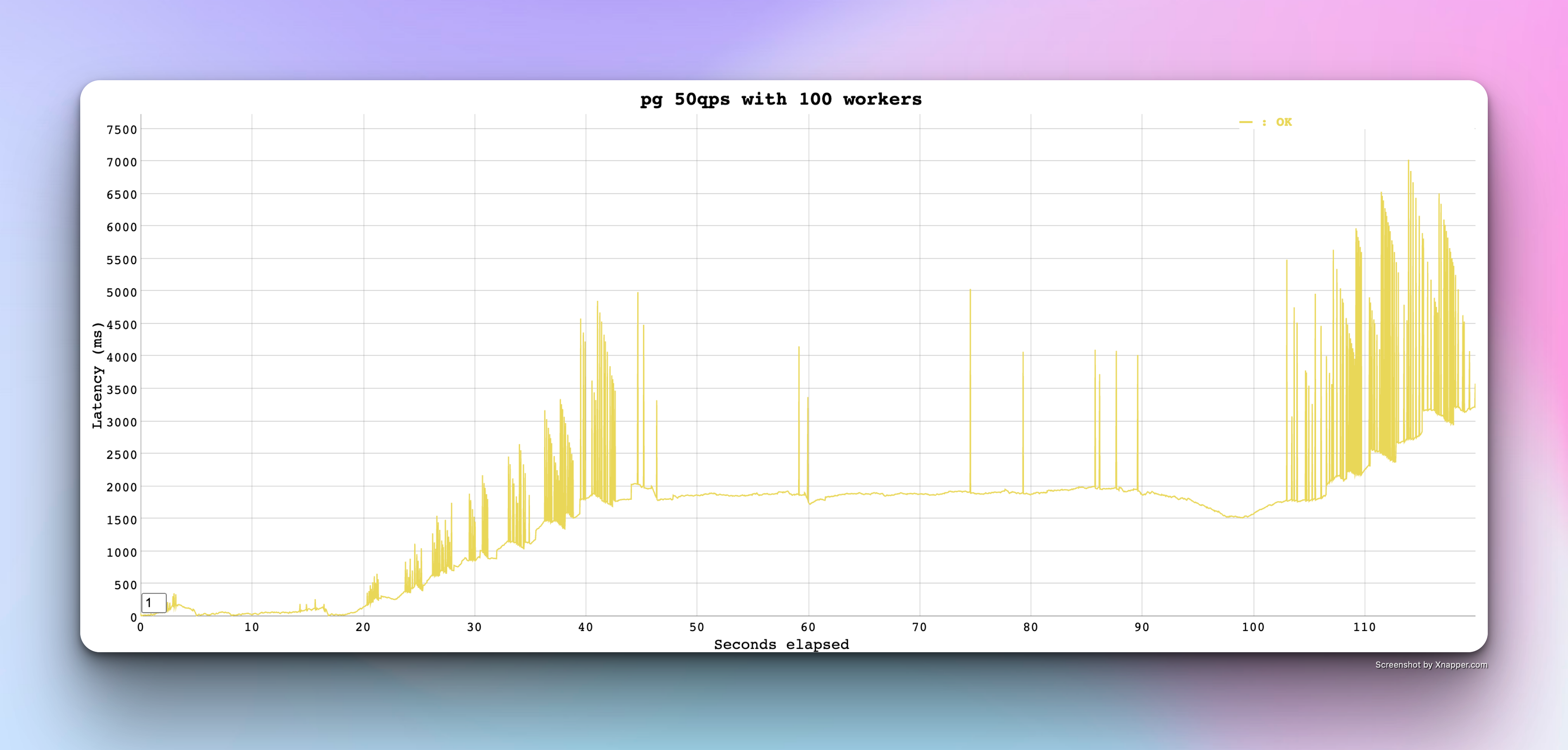
with number of workers set to 100
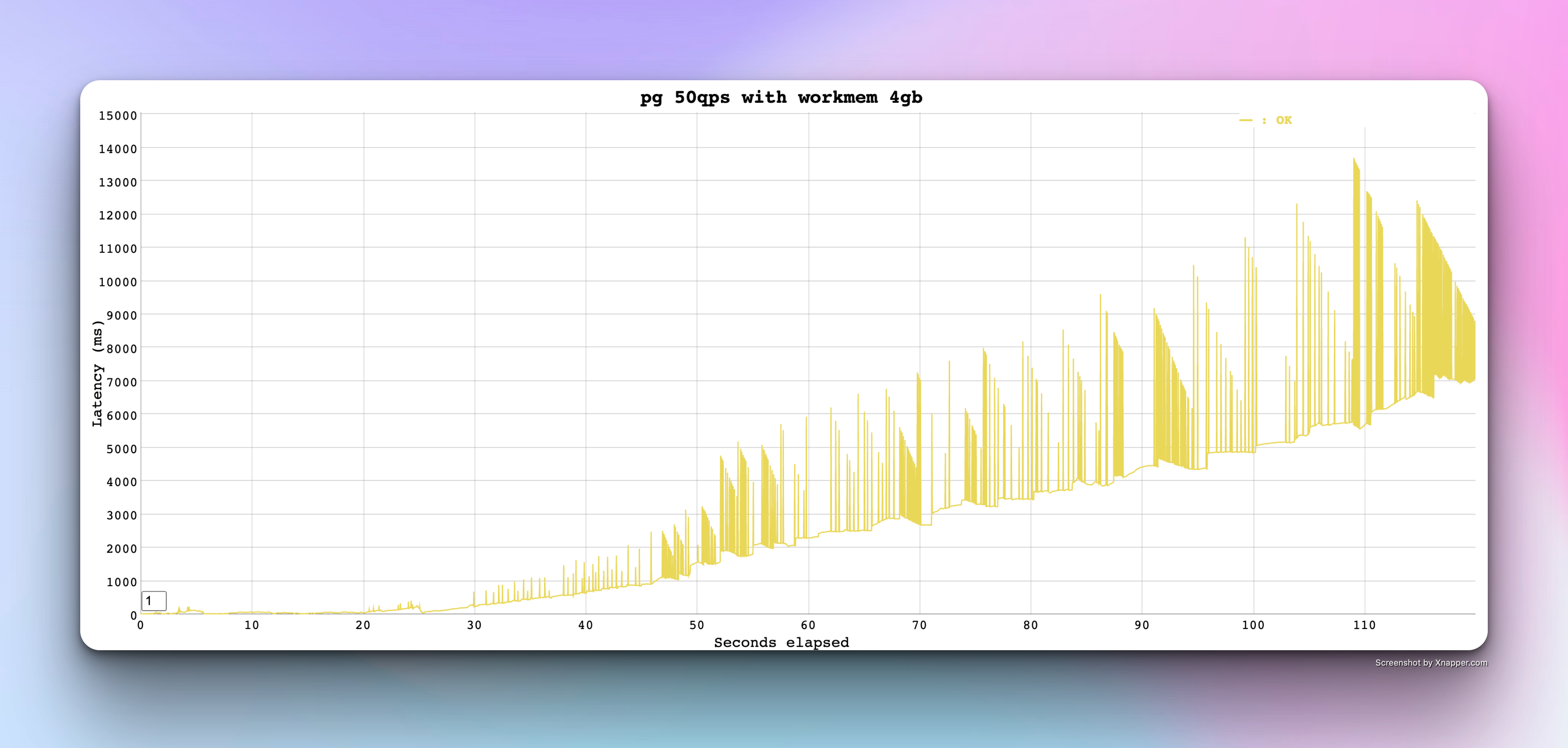
with work_mem increased upto 4GB
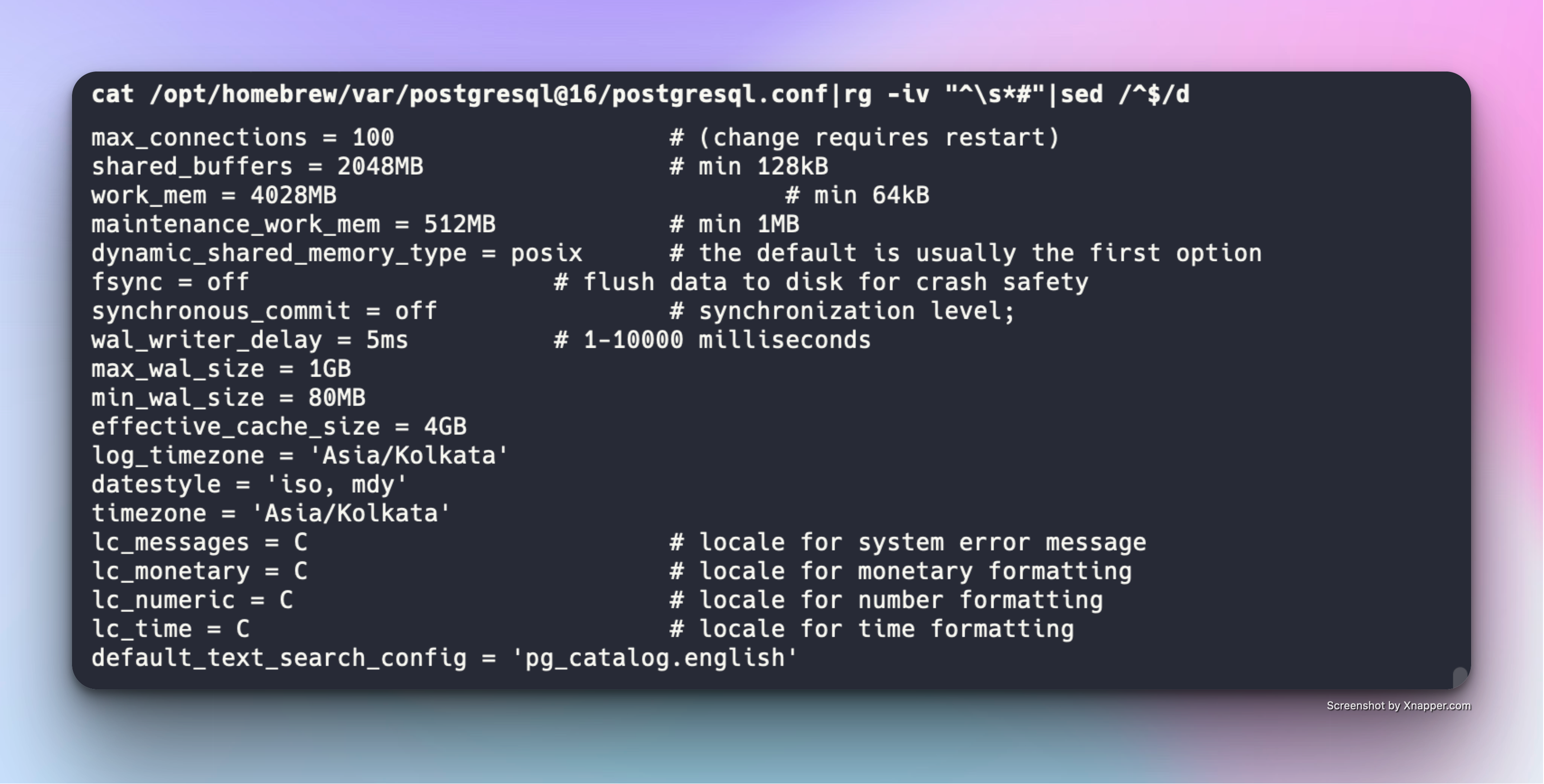
After various changes - this is how my config file looked like at the end of Round 3
Then at the end of Round3 - I strangely noticed something from fastapi logs - Look at the following screenshot and see if you find what are those
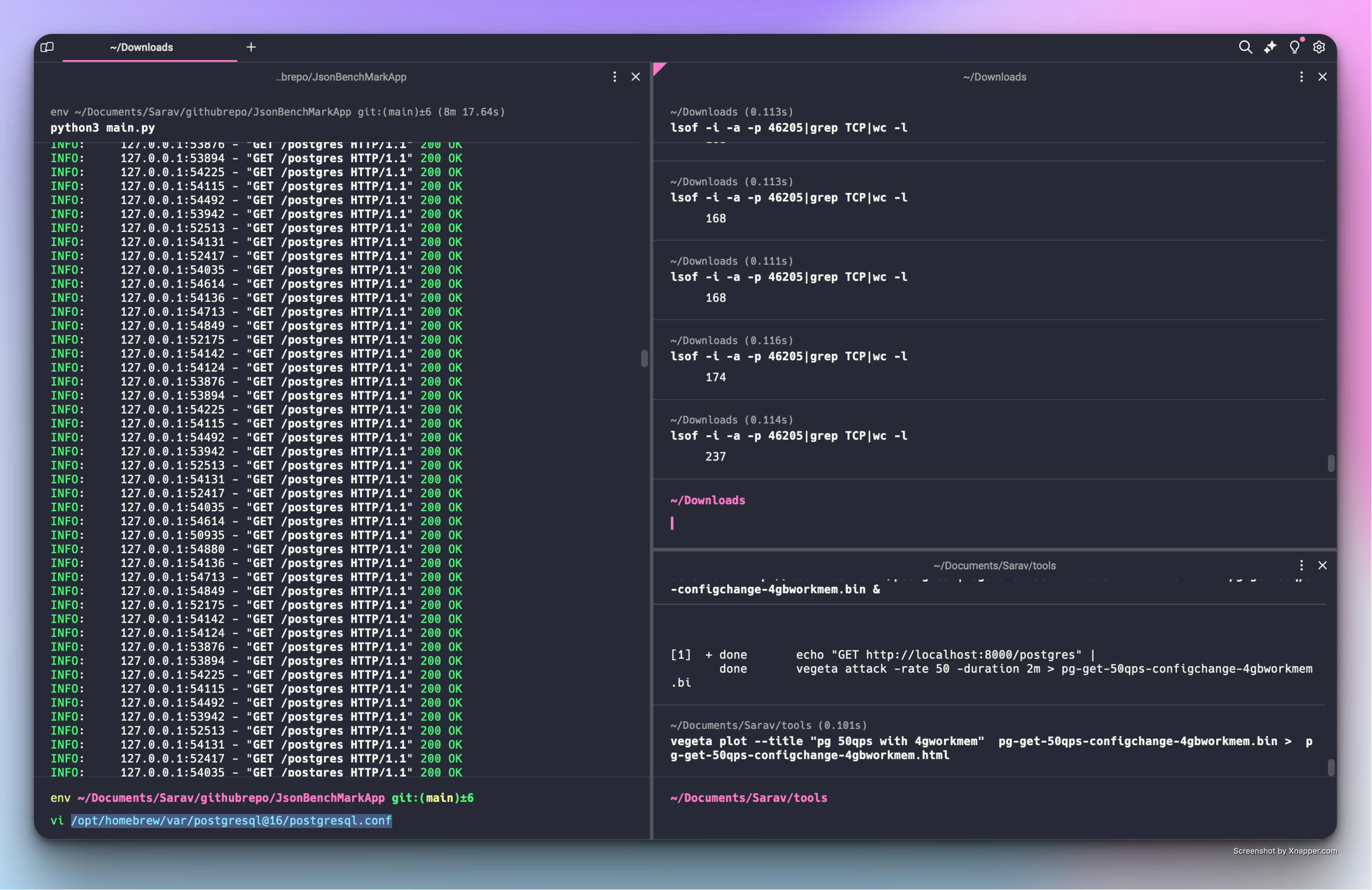
If you already found it great.
Two interconnected things I found odd are
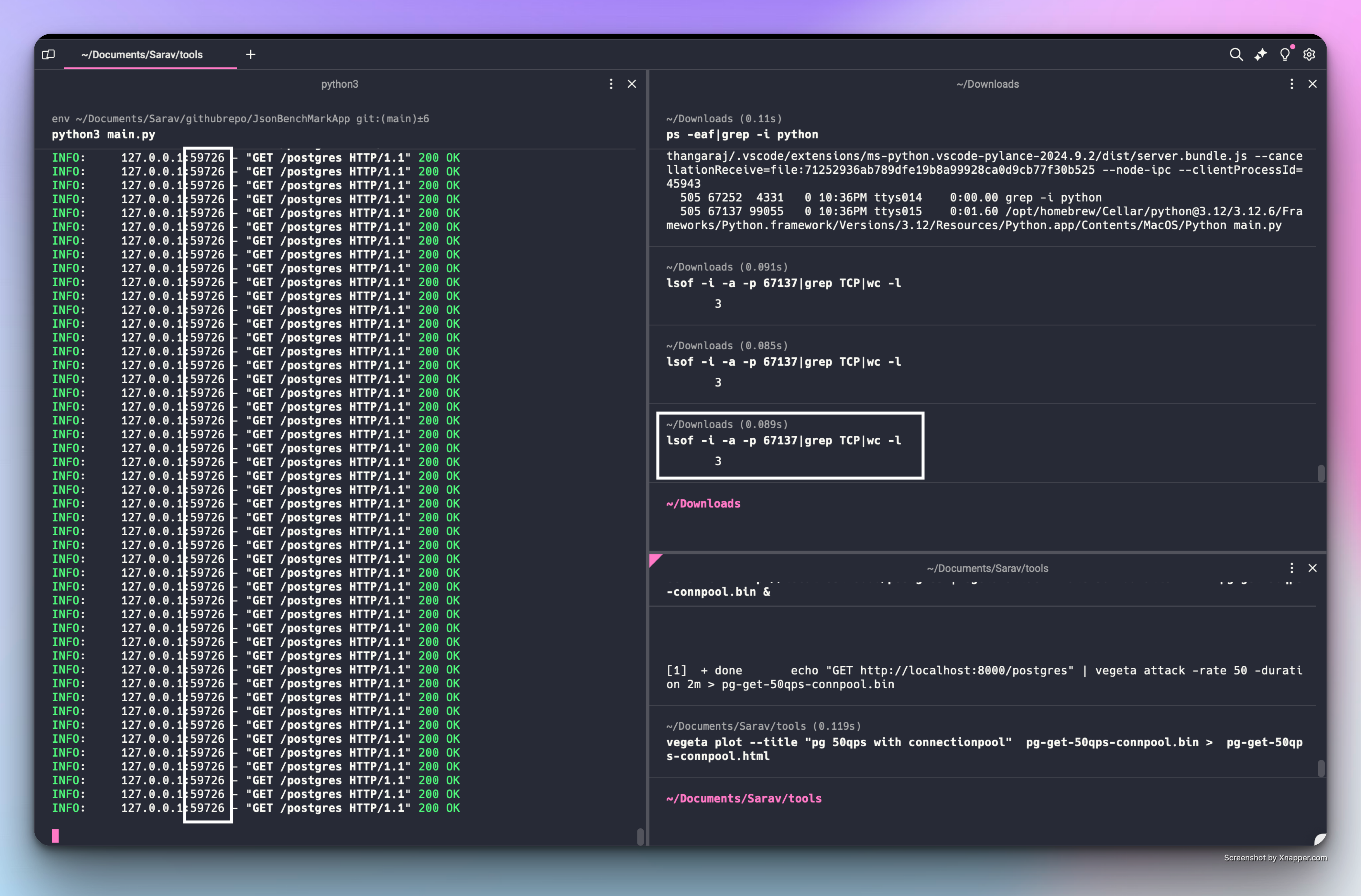
In the FastAPI logs - I noticed a new socket or port for every single request and the lsof command output reaffirmed the no of open TCP connections by the fastapi were constantly increasing.
This made me realize something
Initially I was running this test without closing the connection - so I thought it would make a difference if I close the connection after each request and recreate on demand
Round 4: Closing and reOpening new connection for every call
Here is the snippet and you can see I have added conn.close()
@app.get("/postgres")
async def get_postgres_data(conn=Depends(get_pg_pool_conn)):
with conn.cursor() as cur:
cur.execute("""SELECT
user_data->'user'->>'name' AS name,
SUM((ord->>'total')::DECIMAL(10, 2)) AS total_order_value,
NOW()
FROM
users,
jsonb_array_elements(user_data->'user'->'orders') AS ord
GROUP BY
user_data->'user'->>'name';""")
data = cur.fetchall()
conn.close()
return {"data": data}
Here is the result of the same - It made it worse
But it made me realize the more number of connections we deal with - more the latency
so we need to efficiently manage the connections and reuse it
thats where the connection pool has come in
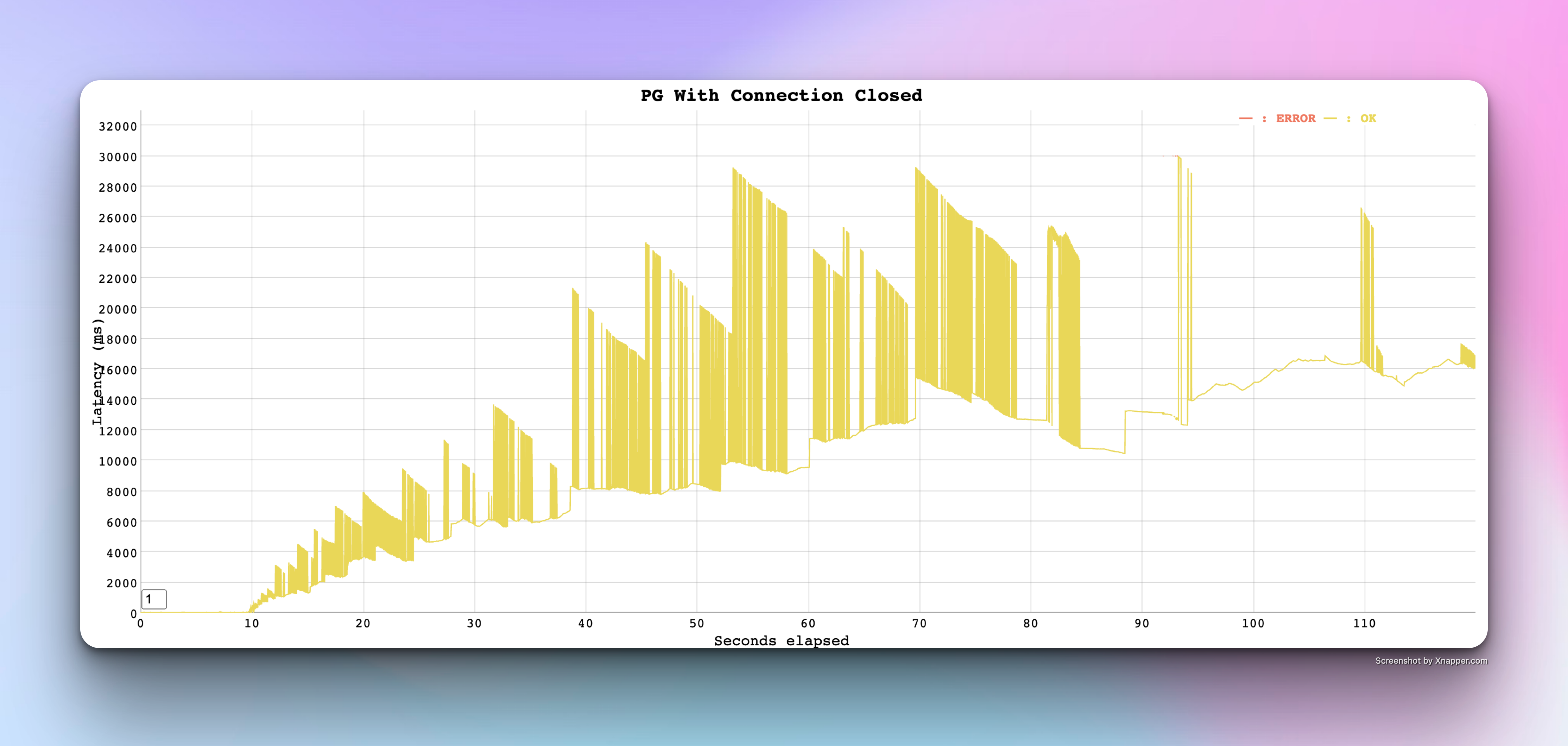
Round 5: PostgreSQL with ConnectionPool
This is where I have started using the connection pool in psycopg2 but I must say - MYSQL is a clear winner in this segment as it efficiently managed the connection on its own with out explicit connection pool
I have added a new connection logic which uses PSYCOPG2's SimpleConnectionPool method to create a connection pool
pool = psycopg2.pool.SimpleConnectionPool(
minconn=1,
maxconn=10,
host=os.environ.get("PG_HOST"),
user=os.environ.get("PG_USER"),
password=os.environ.get("PG_PASS"),
database=os.environ.get("PG_DB")
)
we have set 1 minimum connection and set 10 as a maximum connection and here are the results
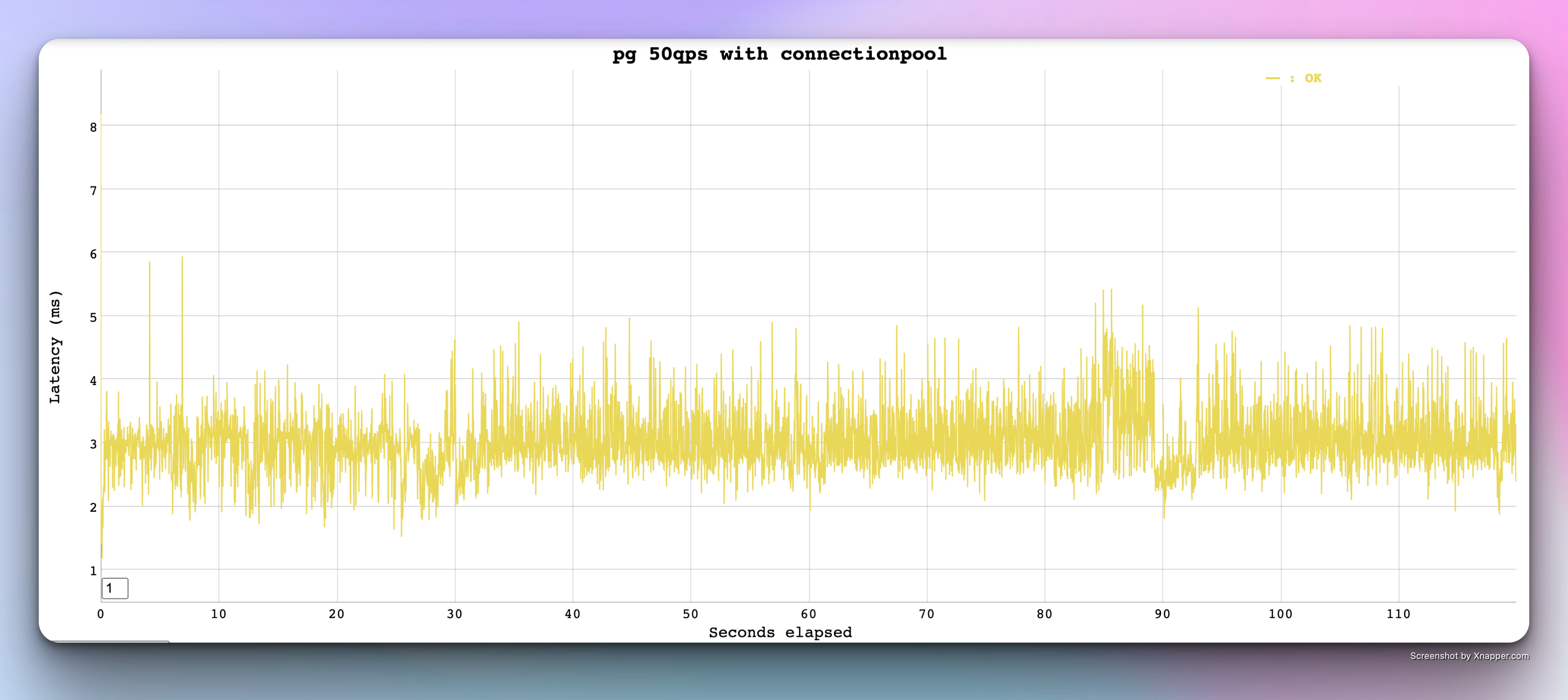
Voila, we have now achieved at least 50% of reduced latency with connection pools and single socket being reused
Final Verdict
While we have achieved a better performance finally with PostgreSQL which indeed proves that it is faster and better than mysql at least by 30 to 50% in our case
Hence proved that PostgreSQL is faster and better and provide easy methods and commands to interact with JSON
This article on cloudbees covered the Postgres JSON capabilities in detail
But to get there, we really have to tune PostgreSQL configuration to a great extent and mysql's batteries included approach is most beneficial if you are looking for less administration tasks later on
While PostgreSQL is powerful and super customizable to meet all your enterprise needs - MYSQL is the no #1 open source database out there and its not falling behind much in terms of performance
MySQL has a big community and great power users like Flipkart, Uber, Spotify etc - In fact, Uber have migrated from PG to Mysql recently as they claimed in their blog here
So the verdict is - PostgreSQL is a better if you are ready to invest time and efforts for the performance boost of 30 to 40%. MySQL is great for all scales and usecases starting from local development to enterprise use case but they have to still catchup on the JSON space
Cheers
Sarav AK

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content




