How to list all repositories in BitBucket, the same question I had and when I was searching in the community I found a script and I made some modifications on top of it and sharing it with you all.
So, I hope you are all aware that BitBucket has the REST API interface which can be invoked by sending your bitbucket credentials in BasicAuth headers and it reveals pretty much all the info what their UI does.
Documentation on BitBucket Rest API can be found here

Testing the BitBucket Rest API in postman
Here is the postman sample screenshot
You have to use the API endpoint along with your team name or account identifier. Something like https://api.bitbucket.org/2.0/repositories/gritfy
Choose the Basic Auth and Enter the Username and Password and send a request and that's all. You would see the data being returned.
The result is usually JSON data.
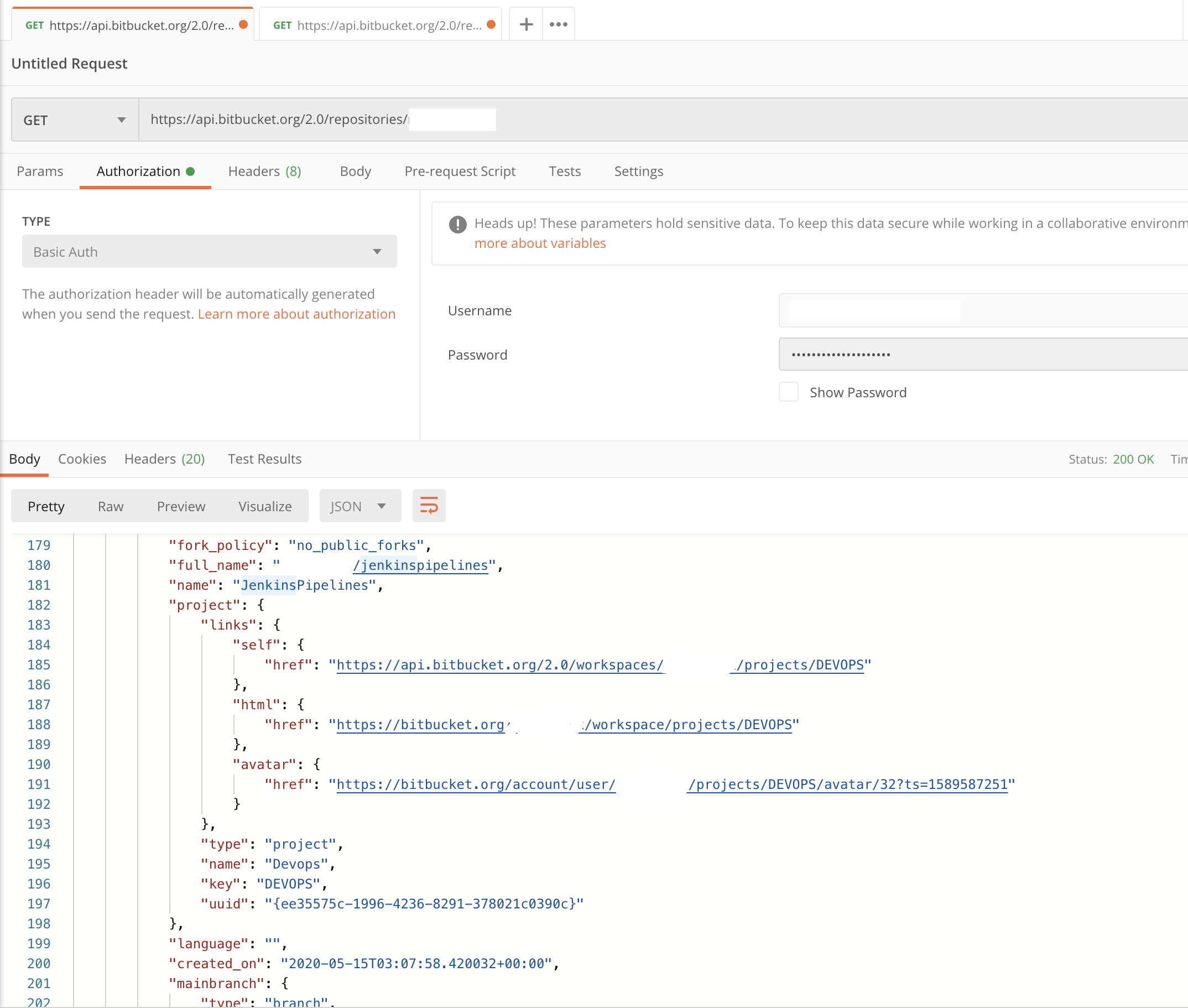
Filtering the outputs with Filter Query
The Rest API, by default, provides a lot of information which is not needed in all the cases. Especially for our current requirement of listing the repository names and their URLs
So you can use the fields query string in your API call like shown below to choose a specific JSON data, in our case it is values.links
https://api.bitbucket.org/2.0/repositories/myrepo?
fields=values.links
Enabling the Pagination when you have more Repositories
When you have a huge number of repositories rather letting the API call run for a long time you can actually do the pagination and load on demand.
The BitBucket Rest API also provides a way to handle the pagination when you have more number of repositories to handle and when you do not want to wait indefinitely
https://api.bitbucket.org/2.0/repositories/myrepo?
pagelen=10
For example, if you have 100 repositories in your bitbucket with pagination you can load it for 10 times.
Python Script to List All Repositories in BitBucket
Here is the python script designed to list all repositories in your BitBucket this also handle the pagelen and fields
The endpoint URL we are using here is this.
https://api.bitbucket.org/2.0/repositories/myrepo?pagelen=10&fields=next,values.links.clone.href,values.slug
Here is the complete script
import requests
from requests.auth import HTTPBasicAuth
##Login
username = 'username'
password = 'password'
team = 'myteam'
full_repo_list = []
# Request 100 repositories per page (and only their slugs), and the next page URL
next_page_url = 'https://api.bitbucket.org/2.0/repositories/%s?pagelen=10&fields=next,values.links.clone.href,values.slug' % team
# Keep fetching pages while there's a page to fetch
while next_page_url is not None:
response = requests.get(next_page_url, auth=HTTPBasicAuth(username, password))
page_json = response.json()
# Parse repositories from the JSON
for repo in page_json['values']:
reponame=repo['slug']
repohttp=repo['links']['clone'][0]['href'].replace('SaravThangaraj@','')
repogit=repo['links']['clone'][1]['href']
print reponame+","+repohttp+","+repogit
full_repo_list.append(repo['slug'])
# Get the next page URL, if present
# It will include same query parameters, so no need to append them again
next_page_url = page_json.get('next', None)
# Result length will be equal to `size` returned on any page
print ("Result:", len(full_repo_list))
The result would be Comma Separated Values(CSV) which you can redirect to some file with .csv extension which can be opened in excel for better readability and formatting
Cheers
SaravAK

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content