
In this brief article, I want to share a few tricks and lessons I have learnt on Converting Latin1 Encoded rows to UTF8
I had a table with a field named username with millions of records and we recently converted that table from latin1 charset to UTF8
First, let's start by learning how to check the default charset and collation of our tables and databases

the following SQL query would list all the databases and their Charset and collation
SELECT SCHEMA_NAME 'database', default_character_set_name 'charset', DEFAULT_COLLATION_NAME 'collation' FROM information_schema.SCHEMATA;
the result would be something like this
mydatabase> SELECT SCHEMA_NAME 'database', default_character_set_name 'charset', DEFAULT_COLLATION_NAME 'collation' FROM information_schema.SCHEMATA; +----------------------+---------+-------------------+ | database | charset | collation | +----------------------+---------+-------------------+ | information_schema | utf8 | utf8_general_ci | | analytics | latin1 | latin1_swedish_ci | | testing | utf8 | utf8_general_ci | | innodb | latin1 | latin1_swedish_ci | | business | latin1 | latin1_swedish_ci | | hr | latin1 | latin1_swedish_ci | | mysql | utf8 | utf8_general_ci | | blog | latin1 | latin1_swedish_ci | | percona_schema | latin1 | latin1_swedish_ci | | performance_schema | utf8 | utf8_general_ci | | rs_db | utf8 | utf8_general_ci |
If you want to go down further and check the charset of every table on every database in your MySQL you can use the following query
SELECT CCSA.character_set_name, T.table_schema, T.table_name FROM information_schema.`TABLES` T, information_schema.`COLLATION_CHARACTER_SET_APPLICABILITY` CCSA WHERE CCSA.collation_name = T.table_collation
Once you are aware what are the latin1 encoded tables you can start the conversion process.
Difference between utf8 and utf8mb4 in MYSQL
When you use UTF8 in MySQL, you consider it is equivalent to world standard UTF-8 Charset which supports literally any character in the modern era.
But the utf8 in MySQL is a misnomer, while the global standard UTF-8 can store 4 bytes of Unicode characters, MySQL's utf8 can store only 3 bytes
These 4-byte Unicode characters are also known as astral planes the best example of the Astral plane are emojis
What is Astral Plane ( click to expand )
Astral symbols refer to the characters that are outside of the Basic Multilingual Plane (BMP) in the Unicode standard. The Unicode standard is a system for encoding all of the world's characters, and it divides its character set into multiple planes:
Basic Multilingual Plane (BMP): This covers Unicode code points from U+0000 to U+FFFF. Most of the commonly used characters, including most characters in major world languages and many symbols, are encoded here.
Astral Planes: These are the planes beyond the BMP, namely:
- Supplementary Multilingual Plane (SMP): U+010000 to U+01FFFF
- Supplementary Ideographic Plane (SIP): U+020000 to U+02FFFF
- Special-purpose Supplementary Plane (SSP): U+0E0000 to U+0EFFFF
- Two reserved planes: U+030000 to U+03FFFF and U+040000 to U+04FFFF
Characters in the astral planes are often less commonly used. Examples include
- Ancient or historic scripts
- Lesser-used modern scripts
- Many emojis
- Mathematical symbols
- Musical notation symbols
using utf8 instead of utf8mb4 does not end in causing data loss but leads to security risks too
Here is one famous example from the Spotify Engineering Blog
Now I hope you understand the limitations of utf8 in MySQL and many reasons to choose utf8mb4 in MySQL over the latter.
In fact, MySQL’s utf8 only allows you to store 5.88% ((0x00FFFF + 1) / (0x10FFFF + 1)) of all possible Unicode code points. Proper UTF-8 can encode 100% of all Unicode code points.
Conversion to UTF8 using ALTER - Mysql
You can actually change the charset at various levels using ALTER
Convert the entire database to utf8mb4
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;To Convert a single table
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
To Convert Columns ( Be mindful of the datatype, I've used a sample column with Varchar)
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
But that's not the scope of our article, we are going to see how to convert latin1 encoded texts on a table using update query and some filters
In Place UPDATE and conversion of Latin1 encoded string to UTF8
We have seen how to alter the entire table and its charset to utf8mb4 but sometimes we might have to deal with already available/inserted data from different charset
let's see this with an example
I have a table named utf8testing with the charset utf8mb4
MySQL root@(none):testdb> SELECT CCSA.character_set_name, T.table_schema, T.table_name FROM information_schema.`TABLES` T, information_schema.`COLLATION_CHARACTER_SET_APPLICABILITY` CCSA WHER -> E CCSA.collation_name = T.table_collation and T.table_name = 'utf8testing' +--------------------+--------------+-------------+ | character_set_name | table_schema | table_name | +--------------------+--------------+-------------+ | utf8mb4 | testdb | utf8testing | +--------------------+--------------+-------------+ 1 row in set Time: 0.019s
But I am going to insert a Latin1 encoded string by setting my MySQL client charset to latin1
MySQL root@(none):testdb> set names latin1;
Query OK, 0 rows affected
Time: 0.000s
MySQL root@(none):testdb> insert into utf8testing (username) values ("Sarav🥱")
Query OK, 1 row affected
Time: 0.020s
MySQL root@(none):testdb> select * from utf8testing;
+----------+
| username |
+----------+
| Sarav🥱 |
+----------+
1 row in set
Though it might seem all OK, the moment we change our client charset to utf8mb4 the smiley would go missing
It is because the smiley was inserted as a latin1 encoded string
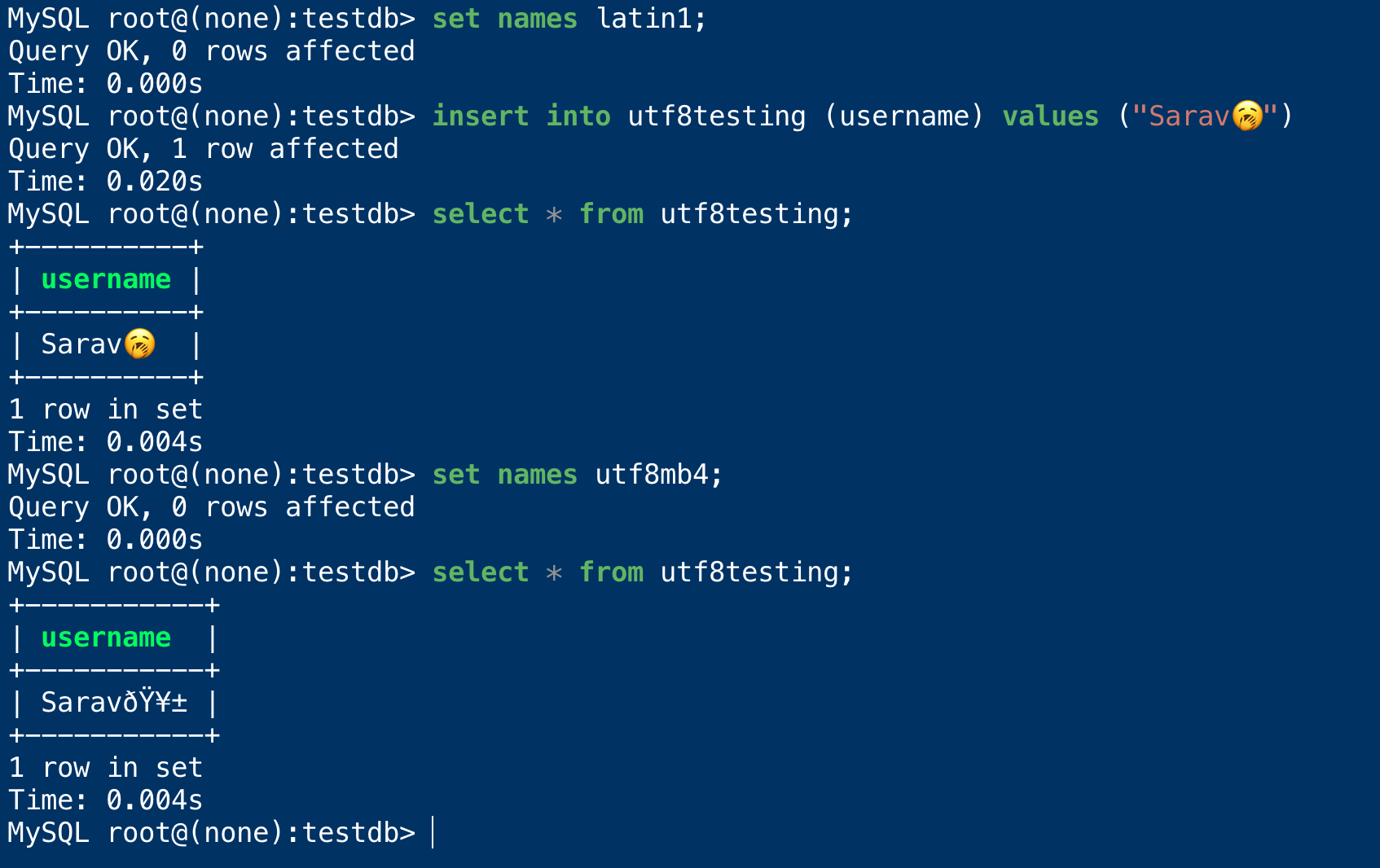
MySQL root@(none):testdb> set names utf8mb4; Query OK, 0 rows affected Time: 0.000s MySQL root@(none):testdb> select * from utf8testing; +-----------+ | username | +-----------+ | Sarav🥱 | +-----------+ 1 row in set Time: 0.004s
Now we need to convert this latin1 encoded but displayed as utf8mb4 string to utf8mb4 in place
we can do this by SQL cast conversion query
update utf8testing set username = convert(cast(convert(username USING latin1)AS BINARY)USING utf8mb4)
But how can you update and convert all the text, what if there is utf8 encoded text? When you try to double encode the result would leads to data loss
let me explain
Finding Only Latin1-encoded texts
To understand this better let's try to insert the same text with a smiley Sarav🥱 with different charsets
Inserting a text with utf8mb4 charset
MySQL root@(none):testdb> set names utf8mb4;
Query OK, 0 rows affected
Time: 0.000s
MySQL root@(none):testdb> insert into utf8testing (username) values ("Sarav🥱-utf8mb4")
Query OK, 1 row affected
Time: 0.015s
MySQL root@(none):testdb> select * from utf8testing;
+-----------------+
| username |
+-----------------+
| Sarav🥱-utf8mb4 |
+-----------------+
inserting another text with latin1 charset
MySQL root@(none):testdb> set names latin1
Query OK, 0 rows affected
Time: 0.014s
MySQL root@(none):testdb> insert into utf8testing (username) values ("Sarav🥱-latin1")
Query OK, 1 row affected
Time: 0.001s
MySQL root@(none):testdb> select * from utf8testing;
+----------------+
| username |
+----------------+
| Sarav?-utf8mb4 |
| Sarav🥱-latin1 |
+----------------+
2 rows in set
Time: 0.008s
MySQL root@(none):testdb>
You can already notice the utf8mb4 encoded text is replaced with ? question mark when you set your client charset to latin1
likewise, if you set your charset to utf8mb4 you would not be able to see the smiley in the latin1 encoded text
MySQL root@(none):testdb> set names utf8mb4; Query OK, 0 rows affected Time: 0.000s MySQL root@(none):testdb> select * from utf8testing; +------------------+ | username | +------------------+ | Sarav🥱-utf8mb4 | | Sarav🥱-latin1 | +------------------+ 2 rows in set Time: 0.006s MySQL root@(none):testdb>
Now we have both utf8mb4 and latin1 encoded texts on our table how would you find and convert only latin1 encoded texts
Workaround to filter UTF8mb4 encoded text
Here is the query I am going to use to find out the latin1 encoded texts
> select * from utf8testing where convert(cast(convert(username USING latin1) AS BINARY) USING utf8mb4) IS NOT NULL AND convert(cast(convert(username USING latin1) AS BINARY) USING utf8mb4) NOT LIKE '%?%' AND length(convert(cast(convert(username USING latin1) AS BINARY) USING utf8mb4)) > 3 +------------------+ | username | +------------------+ | Sarav🥱-latin1 | +------------------+ 1 row in set
As you can see in the preceding SQL query and output, we have successfully filtered out the UTF8 encoded text and only latin1 encoded text is shown
Let's break this query down:
convert(username USING latin1):This converts theusernamefield from its current character set tolatin1encoding.cast(... AS BINARY):This casts the result from step 1 to a binary string. By converting the value to binary, the subsequent operations won't treat it as character data but as raw byte data. This step ensures the accurate preservation of byte sequences during conversions.convert(... USING utf8mb4):This takes the result from step 2 and converts the binary data toutf8mb4encoding.
Now, with an understanding of these conversion operations, let's dissect the WHERE conditions of the query:
IS NOT NULL:This condition ensures that the converted value is not null, i.e., the conversion was successful, and there is data in theusernamefield.NOT LIKE '%?%':This condition checks if the convertedusernamedoes not contain the character?. The?character is significant here because when you convert some incompatible characters between character sets, they might be replaced by a?character. So, this condition ensures that the converted value doesn't have any of these potentially problematic characters.length(...) > 3:This condition ensures that the length of the convertedusernameis greater than 3 characters. It filters out any rows where theusername, after conversion, is 3 characters or shorter.
In summary, the query is selecting all rows from the utf8testing table where the username, after being converted through a series of character encoding transformations, is:
- Not null
- Doesn't contain the
?character - Has a length greater than 3 characters.
I have created these clauses to filter out the Possible Double Encoding scenarios based on the end result.
In other words, when you try to encode the text which is already encoded in utf8mb4 you would end up with NULL characters or ? question marks or a text with a length below 3 characters.
So with this where clause I am trying to convert the rows on the fly and exclude such results without actually committing any change to the table.
after validating the output, I would replace the select with update and confidently convert the latin1 to utf8mb4
Here is a quick sample of what would happen if you try to convert the text which is already utf8mb4
MySQL root@(none):testdb> select username, convert(cast(convert(username USING latin1) AS BINARY) USING utf8mb4) as utf8mb4 from utf8testing +------------------+----------------+ | username | utf8mb4 | +------------------+----------------+ | Sarav🥱-utf8mb4 | Sarav?-utf8mb4 | | Sarav🥱-latin1 | Sarav🥱-latin1 | +------------------+----------------+ 2 rows in set Time: 0.008s
You can notice, the text with utf8mb4 encoding is losing the smiley and replaced with ? when we try to double-convert
Double Conversion is really risky so be mindful and validate the select query result twice before update
Hope you now understand why we added this condition to our query
convert(cast(convert(username USING latin1) AS BINARY) USING utf8mb4) NOT LIKE '%?%'
Important Caveats
- This is a workaround, please proceed with caution before trying this at your end
- While these
whereclauses with?and char length below 3 suits my requirement, it may not suit you show validate the result of theselectquery before youupdate - Since we are trying to filter based on
?if your text contains?already this may not work or fail.
I am sharing these queries to show you different options and share my own personal experience
Please feel free to let me know if there are better ways to do this over comments
Update query - to Convert Latin1 to UTF8 with Filtering
We just learnt how to filter already utf8mb4 encoded texts, using on-demand conversion in WHERE clause
Hope you have validated the output of the Select query and ensured that the result is OK without any data loss
Feel free to tweak the where clause with more conditions before you come here for the update
In my case, the select query we have used is just fine
select *
from utf8testing
where convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
) IS NOT NULL
AND convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
) NOT LIKE '%?%'
AND length(
convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
)
) > 3
Now let us replace the select with an update and do the actual conversion, Here is the update query
update utf8testing
set username = convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
)
where convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
) IS NOT NULL
AND convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
) NOT LIKE '%?%'
AND length(
convert(
cast(convert(username USING latin1) AS BINARY) USING utf8mb4
)
) > 3
Here is the execution screenshot and the result of the preceding UPDATE query
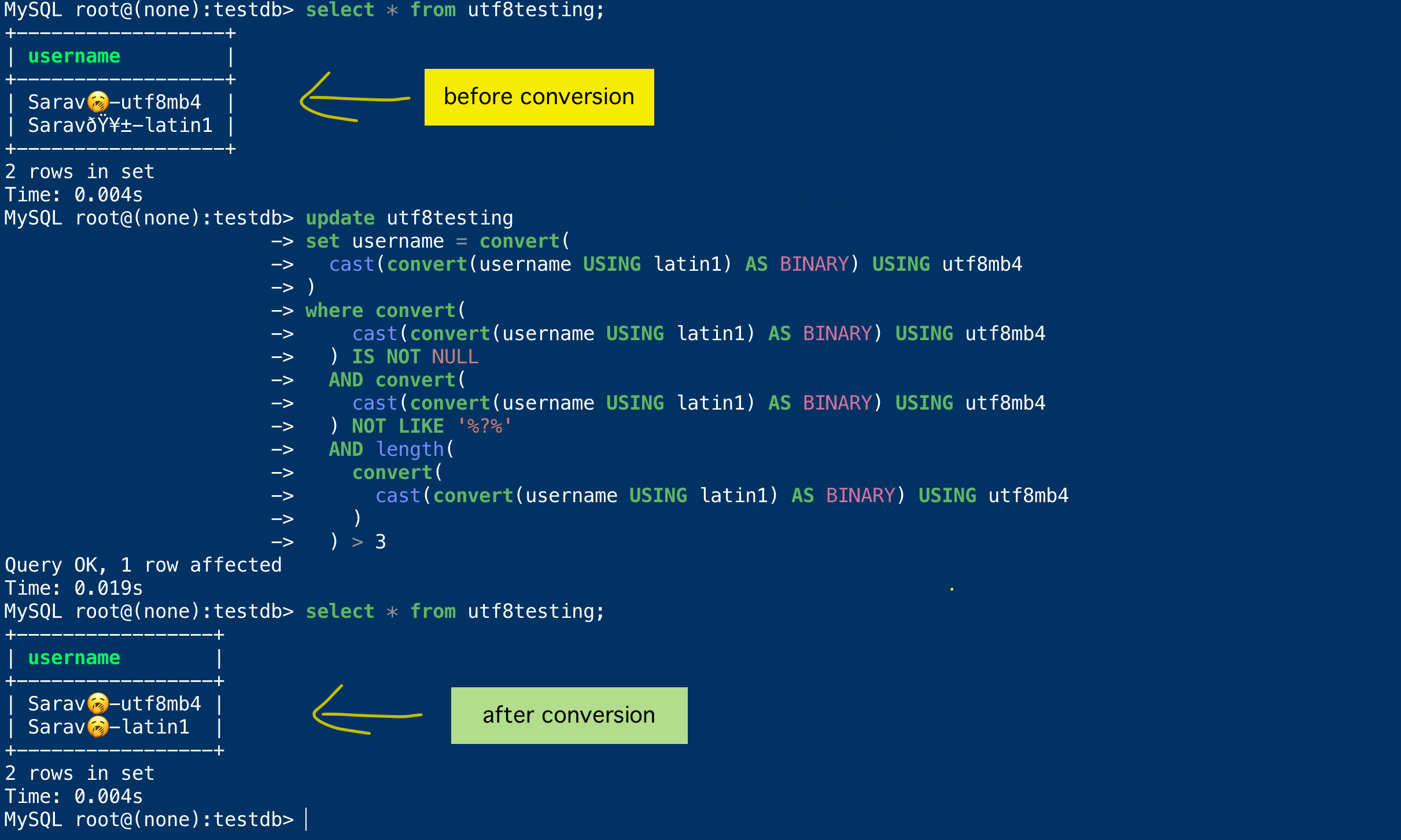
You can see from the preceding screenshot that we have successfully found and converted only the `latin1` encoded text without touching the other records
Conclusion
As I have mentioned in the caveat section earlier, this article and the examples are to show how we can find latin1 encoded text in a table and convert them to utf8 using specific WHERE conditions
But you have to validate the result of the SELECT query and see if it is matching your expectations before going for UPDATE
Let me know in the comments section if there are any easy ways or tools you may create or find

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content


